
Отличие графа от дерева
Обновлено: 18.09.2024
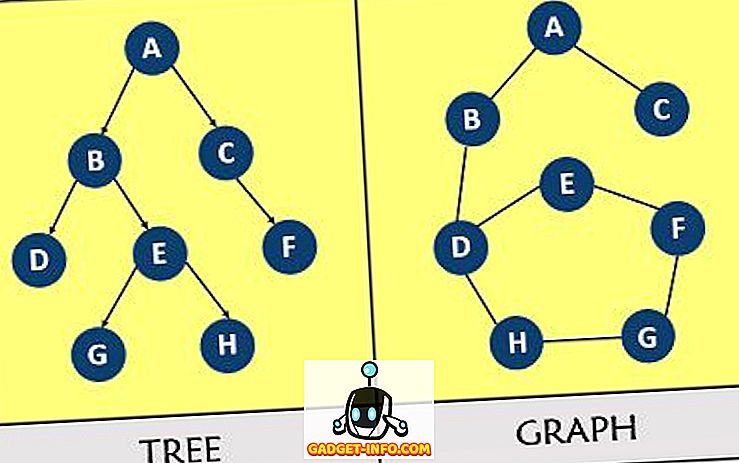
Дерево и граф относятся к категории нелинейных структур данных, где дерево предлагает очень полезный способ представления отношений между узлами в иерархической структуре, а граф следует сетевой модели. Дерево и граф различаются тем, что древовидная структура должна быть соединена и не может иметь петель, в то время как в графе таких ограничений нет.
Нелинейная структура данных состоит из набора элементов, которые распределены на плоскости, что означает, что между элементами нет такой последовательности, как в линейной структуре данных.
Сравнительная таблица
| Основа для сравнения | дерево | график |
|---|---|---|
| Дорожка | Только один между двумя вершинами. | Допускается более одного пути. |
| Корневой узел | У него ровно один корневой узел. | Граф не имеет корневого узла. |
| Loops | Петли не допускаются. | График может иметь петли. |
| сложность | Менее сложный | Более сложный сравнительно |
| Методы обхода | Предварительный заказ, заказ и заказ. | Поиск в ширину и поиск в глубину. |
| Количество ребер | n-1 (где n - количество узлов) | Не определен |
| Тип модели | иерархическая | сеть |
Определение дерева
Дерево - это конечная коллекция элементов данных, обычно называемых узлами. Как упомянуто выше, дерево представляет собой нелинейную структуру данных, которая упорядочивает элементы данных в отсортированном порядке. Он используется для отображения иерархической структуры между различными элементами данных и организует данные в ветви, которые связывают информацию. Добавление нового ребра в дерево приводит к образованию петли или цепи.
Существует несколько типов деревьев, таких как двоичное дерево, двоичное дерево поиска, дерево AVL, потоковое двоичное дерево, B-дерево и т.д. структура данных.
Свойства дерева:
- В верхней части дерева есть обозначенный узел, известный как корень дерева.
- Остальные элементы данных делятся на непересекающиеся подмножества, называемые поддерево.
- Дерево расширяется в высоту по направлению к низу.
- Дерево должно быть связано, что означает, что должен быть путь от одного корня ко всем остальным узлам.
- Не содержит петель.
- Дерево имеет n-1 ребер.
Существуют различные термины, связанные с деревьями, такие как конечный узел, ребро, уровень, степень, глубина, лес и т. Д. Среди этих терминов некоторые из них описаны ниже.
- Край - линия, которая соединяет два узла.
- Уровень - дерево делится на уровни таким образом, что корневой узел находится на уровне 0. Затем его непосредственные дочерние элементы находятся на уровне 1, а его непосредственные дочерние элементы находятся на уровне 2 и т. Д. Вплоть до конечного или конечного узла.
- Степень - это число поддеревьев узла в данном дереве.
- Глубина - это максимальный уровень любого узла в данном дереве, также известный как высота .
- Терминальный узел - узел самого высокого уровня является терминальным узлом, в то время как другие узлы, кроме терминального и корневого узла, называются нетерминальными узлами.
Определение графика
График также представляет собой математическую нелинейную структуру данных, которая может представлять различные виды физической структуры. Он состоит из группы вершин (или узлов) и набора ребер, которые соединяют две вершины. Вершины на графике представлены в виде точек или окружностей, а ребра показаны в виде дуг или отрезков. Ребро представлено E (v, w), где v и w - пары вершин. Удаление ребра из схемы или связного графа создает подграф, который является деревом.
Графы подразделяются на различные категории, такие как направленные, ненаправленные, связные, несвязные, простые и мультиграфы. Компьютерная сеть, транспортная система, граф социальной сети, электрические схемы и планирование проекта - вот некоторые из приложений структуры данных графа. Он также используется в технике управления, которая называется PERT (метод оценки и анализа программ) и CPM (метод критического пути), в которой анализируется структура графа.
Свойства графика:
- Вершина в графе может быть соединена с любым числом других вершин, используя ребра.
- Край может быть двунаправленным или направленным.
- Ребро может быть взвешено.
В графе также используются различные термины, такие как смежные вершины, путь, цикл, степень, связный граф, полный граф, взвешенный граф и т. Д. Давайте разберемся с некоторыми из этих терминов.
- Смежные вершины - вершина a смежна с вершиной b, если есть ребро (a, b) или (b, a).
- Путь - путь из случайной вершины w является смежной последовательностью вершин.
- Цикл - это путь, в котором первая и последняя вершины совпадают.
- Степень - это число ребер, падающих на вершину.
- Связный граф. Если существует путь от случайной вершины до любой другой вершины, то этот граф называется связным графом.
Ключевые различия между деревом и графиком
- В дереве существует только один путь между любыми двумя вершинами, тогда как граф может иметь однонаправленные и двунаправленные пути между узлами.
- В дереве есть ровно один корневой узел, и у каждого дочернего элемента может быть только один родительский узел. В отличие от этого, в графе отсутствует понятие корневого узла.
- У дерева не может быть циклов и автопетлей, в то время как в графе могут быть циклы и автопетли.
- Графики более сложны, так как могут иметь циклы и циклы. Деревья, напротив, просты по сравнению с графиком.
- Дерево пересекается с использованием методов предварительного заказа, по порядку и после заказа. С другой стороны, для обхода графа мы используем BFS (поиск по ширине) и DFS (поиск по глубине).
- Дерево может иметь n-1 ребер. Наоборот, в графе нет заранее определенного числа ребер, и это зависит от графа.
- Дерево имеет иерархическую структуру, тогда как граф имеет сетевую модель.
Заключение
График и дерево представляют собой нелинейную структуру данных, которая используется для решения различных сложных задач. Граф - это группа вершин и ребер, где ребро соединяет пару вершин, тогда как дерево рассматривается как минимально связанный граф, который должен быть связным и свободным от петель.

В чем разница между деревом и графиком - Разница Между
Содержание:
главное отличие между деревом и графиком является то, что дерево организует данные в виде древовидной структуры в иерархии, в то время как граф организует данные в виде сети.
Структура данных - это способ систематизировать данные. Существует в основном два типа структур данных: линейные структуры данных и нелинейные структуры данных. И, две общие нелинейные структуры данных - это дерево и граф.
Ключевые области покрыты
1. Что такое дерево
- определение, функциональность
2. Что такое график
- определение, функциональность
3. В чем разница между деревом и графиком
- Сравнение основных различий
Основные условия
Двоичный поиск, график, линейные структуры данных, нелинейные структуры данных, дерево

Что такое дерево
Дерево - это структура данных, которая упорядочивает данные подобно дереву. Узел - это элемент данных в дереве. Главный узел - это корень, а остальные узлы - его дочерние узлы. Все эти другие узлы расположены в непустых наборах, где каждый из них является поддеревом. Более того, между узлами есть родительско-дочерние отношения. Один родительский узел может иметь несколько дочерних узлов, и для каждого дочернего узла может быть только один родительский узел.

Некоторые важные термины, связанные с деревом, заключаются в следующем. Вы можете увидеть эти функции и примеры в приведенном выше дереве.
корень узел самый верхний элемент данных в дереве. Элемент 8 является корневым узлом на изображении выше.
край помогает связать узлы. Например, в приведенном выше дереве ребра соединяются 8 и 3, 8 и 10.
родитель узел это узел, отличный от корневого узла, который соединяется с ребром вверх. Например, 3 является родительским узлом 1 и 6. Аналогично, 6 является родительским узлом 4 и 7.
ребенок узел это узел, который соединяется вниз по ребру. Например, 4 и 7 являются дочерними узлами 6.
лист узел это узел, который не имеет дочерних узлов. 1, 4,7,13 - листовые узлы в вышеприведенном дереве.
Subtree является потомком узла. Например, раздел слева от корневого узла (8), который начинается с 3, является поддеревом. Точно так же раздел справа от корневого узла, который начинается с 10, является поддеревом.
уровень представляет поколение узлов. Например, корневой узел принадлежит уровню 0. 3, а 10 принадлежит уровню 1 и так далее.
Кроме того, существует два основных типа дерева: двоичное дерево и двоичное дерево поиска. В двоичном дереве каждый узел может иметь максимум 2 дочерних узла. Двоичное дерево поиска - это упорядоченное двоичное дерево.
Что такое график
Граф - это структура данных, представляющая графическую структуру набора объектов, которая связывает некоторые пары объектов ссылками. Обычно графики помогают представлять сети.
Некоторые важные термины, связанные с графиком, заключаются в следующем.
вершины являются объектами или элементами данных. Круги представляют их. На приведенном выше графике A, B, C и D - вершины. Мы также можем написать вершины как V = .
Ребра ссылки, соединяющие вершины Например, ребра выше соединяют вершины A и B, вершины B и D и т. Д. Мы также можем записать ребра как E =
Дорожка представляет последовательность узлов, чтобы следовать для достижения узла назначения. Например, ABD представляет путь от вершины A до D.
Когда два узла соединяются друг с другом через ребро, они смежные узлы, Например, A и B являются смежными узлами. Аналогично, B и D являются смежными узлами.
Основные операции, которые мы можем выполнять над графами, - это добавление вершин, добавление ребер и отображение вершин.
В основном, есть два типа графов как ориентированные и неориентированные графы. Когда граф содержит упорядоченную пару вершин, это ориентированный граф, а когда граф содержит неупорядоченную пару вершин, это неориентированный граф.
Разница между деревом и графиком
Определение
Дерево - это структура данных, которая имитирует иерархическую древовидную структуру с корневым значением и поддеревьями дочерних узлов с родительским узлом, тогда как граф - это структура данных, которая состоит из группы вершин, соединенных через ребра. Таким образом, это принципиальная разница между деревом и графом.
Кроме того, два основных типа деревьев - это двоичное дерево и двоичное дерево поиска. Принимая во внимание, что два основных типа графов - это ориентированные и неориентированные графы.
Представление данных
Дерево представляет данные в форме древовидной структуры иерархически, в то время как график представляет данные, аналогичные сети. Следовательно, в этом главное отличие дерева от графа.
Корневой узел
Кроме того, еще одно важное отличие дерева от графа состоит в том, что в дереве есть корневой узел, а в графе нет корневых узлов.
Loops
Более того, наличие петель является еще одним отличием дерева от графа. В дереве нет циклов, а в графе могут быть циклы.
сложность
Кроме того, граф более сложен, чем дерево.
Заключение
Дерево и граф - это две нелинейные структуры данных. Основное различие между деревом и графиком состоит в том, что дерево организует данные в форме древовидной структуры в иерархии, в то время как граф организует данные в виде сети.
Возможно ли (и как) объяснить разницу между графом и деревом на бытовом уровне? Как сразу понять - граф перед тобой или дерево? Картинки видел, но выразить отличие не могу. Спасибо Вам за Ваше время.
Последний раз редактировалось caxap 08.07.2011, 17:40, всего редактировалось 2 раз(а).
Дерево - граф, обратное не всегда верно. По-моему, у дерева всегда лишь один вход в каждый узел - и вообще это имеет смысл говорить лишь для направленных графов (у которых на каждом ребре указано направление).
С уважением, Gortaur.
А вообще, граф его по воротнику гармошкой видно и входа у него два снизу (ноги), а у дерева один (ствол).
Итак, дерево - граф без циклов.
Что такое эти циклы? Типа что нельзя в тот же узел вернуться?
Последний раз редактировалось caxap 08.07.2011, 18:36, всего редактировалось 3 раз(а).
![$\begin</p>
<p>Нет (например, тогда у вас граф \draw (0,0)--(.6,0); \fill [color=black] (0,0) circle (2.5pt); \fill [color=black] (.6,0) circle (2.5pt); \end$](https://dxdy-04.korotkov.co.uk/f/f/e/7/fe75745cde182b52e1fd9466f964717a82.jpg)
имеет цикл). Позвольте спросить: к чему все эти колхозно-бытовые упрощения? Вы собираетесь 5-летнему ребёнку рассказать основы теории графов?
Если нет, то почему бы просто не почитать учебник. Путь, цепь, цикл, связность, дерево. -- довольно простые понятия и нет смысла их упрощать, когда ничего не стоит их понять их в строгом смысле.

Предлагаем укрепить (или получить) знания о базовых структурах данных. Эти понятия являются основой всего, что связано с программами. Вспомните азы, а если не знаете – получите их. Они пригодятся в работе, а если есть цель найти ее, то и при прохождении интервью. Укажите, что вы знаете составляющие структуры данных, их применение, и это поможет в поиске работы. Потратив немного времени, вы приятно удивите интервьюера, начальника или коллег по работе.
Основополагающие сведения о структурах данных
Структуры данных делятся на:
- линейные (стеки, очереди, массивы) – элементы выстраиваются в последовательность либо линейный список. Также линейны и обходы узлов;
- нелинейные (графы, деревья) – данные выстраиваются без какой-либо последовательности. Также не линейны и обходы узлов.
Коснемся основных действий. Данные можно получить, найти, добавить, удалить. Для реализации этих целей существует много разнообразных структур данных. Каждая отдельно взятая более эффективна в одних вопросах и менее эффективна в других. Потому разработчик должен понимать функциональные составляющие каждой структуры. Грамотное применение функциональных свойств структуры данных ускорит решение любой поставленной задачи.
Приходится часто искать информацию – укажите одну разновидность. Если нужно постоянно что-либо вставлять – укажите другую. А если частенько приходится выполнять действия по перестановке и удалению – укажите третье решение.
Базовые термины
Перед изучением структуры данных кратко коснемся их основы – терминов, а затем перейдем к применению. К ним относятся:
- Интерфейс – определенный набор операций, поддерживающих структуру данных. Он присущ каждой структуре. Интерфейс может предоставлять только перечень поддерживаемых операций, тип принимаемых параметров и возвращает тип этих операций.
- Реализация – обеспечивает внутреннее представление структуры данных, помогает в определении алгоритмов, которые используются в операциях.
Характеристики
Важными характеристиками структур данных являются:
- Корректность – она должна грамотно реализовывать свой интерфейс.
- Сложность времени – должно использоваться минимальное количество времени на выполнение операций.
- Сложность пространства – при проведении операций память должна использоваться минимально.
Какие проблемы можно решить с помощью структуры данных
В связи с тем, что приложения становятся все более сложными, а количество составляющей информации в них постоянно растет, то возникают три проблемы:
- замедление процесса поиска в связи с ростом данных;
- ограниченная скорость процессоров. Несмотря на то, что она достаточно высокая, с ростом объема информации и она ограничивается;
- многократные запросы через поиск на веб-серверах вызывают сбои в их работе.
Структуры данных помогают в решение вышеперечисленных проблем. Данные можно организовать в структуры таким образом, что поиск будет осуществляться практически мгновенно.
Случаи выполнения
Чтобы провести сравнение временных промежутков, необходимых для выполнения различной структуры, используются следующие случаи:
- худший – сценарий, при котором для выполнения конкретной операции потребуется максимальное время, которое только возможно;
- средний – сценарий, при котором на выполнение операции отводится среднее время;
- наилучший – сценарий, который отображает кратчайший промежуток времени, необходимый для выполнения операции.
Основные виды структур
К основным видам структуры данных относятся:
Массивы
Это наипростейшие и широко используемые структуры данных, в которых элементы следуют один за другим. Представляет собой контейнер, в котором может храниться фиксированное количество однотипных компонентов.
- элементами называют все компоненты, хранящиеся в массиве;
- индексы – местонахождение каждого элемента в массиве выражается целым числовым индексом, используемом для его идентификации.
Размерность массива определяет количество индексов в нем. Они бывают одномерными (называют векторами) и многомерными (массив в середине массива). Массивы могут объявляться разными способами на различных языках программирования.
Некоторые структуры являются производными массивов (стеки, очереди). В массиве каждый элемент имеет индекс (положительное целое числовое значение), соответствующий тому, какую позицию в массиве он занимает.
Язык программирования определяет, с какого значения в массиве начинается нумерация. Во многих языках начальным индексом массива определен 0.
- статическими — характеризуются однородностью данных;
- динамическими – характеризуются непостоянством размера, который может меняться в ходе выполнения программы. Это усложняет процесс, ухудшает быстроту действий, но работа с информацией становится более гибкой;
- гетерогенными – характеризуется неоднородностью данных.
Основные операции, которые поддерживаются массивами:
- Traverse – выставляет один за одним все компоненты массива;
- Insert – добавляет один или несколько элементов по указанному индексу;
- Get – производит возврат элемента по указанному индексу;
- Delete – выполняет удаление элемента по указанному индексу;
- Size – позволяет узнать общую численность элементов, содержащихся в массиве.
Списки
Список является абстрактным типом данных. Существует несколько их разновидностей. Рассмотрим наиболее популярные:
Связные (связанные) списки
Связной список представляет собой массив с конечным множеством элементов (отдельных объектов) и указателями на них.
Каждый объект содержит:
- поле информации (тип данных может быть любым);
- ссылки (указатели) на последующий узел.
Таким образом упорядоченные элементы связного списка связаны друг с другом указателями. Вместе эти группы образуют последовательность.
Как и массив, список лежит в основе понятия классической структуры данных. Их функциональные особенности часто сравнивают, т.к. большинство других структур могут быть реализованы с помощью массивов или связных списков. Последний отличается от массива структурной гибкостью. Доступ к спискам осуществляется последовательно, а к массивам – произвольно.
Связанные списки бывают следующих видов:
- Однонаправленные (односвязные) – каждый узел сохраняет адрес либо ссылку на тот узел, который числится следующим. А узел, являющийся последним, содержит последующий адрес либо ссылку как NULL. Линейные однонаправленные списки встречаются чаще всего.
- Двунаправленные (двусвязные) – имеют две ссылки, которые связаны с каждым отдельным узлом (первая указывает на последующий, вторая – на предыдущий).
- Круговые (кольцевые) – все узлы списка соединены в круг при отсутствии в последнем NULL. Является подвидом двух предыдущих видов связных списков. Они могут быть одно- или двусвязными.
Чтобы односвязный список стал круговым, необходимо в его последний узел вставить указатель на первый элемент. Чтобы двунаправленный список преобразовать в кольцевой, следует добавить две ссылки на узлы: первый и последний.
Операции, являющиеся основными:
- InsertAtEnd – вставка заданного элемента в конце списка;
- InsertAtHead – вставка заданного элемента в начало списка;
- Delete – удаление заданного элемента из списка;
- DeleteAtHead – удаление первого элемента в списке;
- Search – возвращение заданного элемента из списка
- isEmpty – в тем случае, когда список пустой, производится возврат True.
Стеки
Отличное сравнение – стопка тарелок. Чтобы из стопки взять тарелку, необходимо вначале снять верхние тарелки. А положить тарелку можно только на верх стопки.
- Push – вставка в стек элемента наверху;
- Pop – удаление верхнего элемента из стека;
- Pip – отображается содержимое;
- isEmpty – происходит возврат True в случае, когда стек пустой;
- Top – возвращает элемент сверху, не удаляя его из стека.
Чаще всего в программировании применяется:
- стек изменений в редакторе кода, позволяющий быстро делать отмену изменений и возвращаться к предыдущему состоянию;
- стек передвижения по страницам в браузере – позволяет быстро переходить по страницам.
Очереди
Если кратко, то очередью является список, в котором добавление новых элементов допустимо строго в его конец, а извлечение – происходит строго с другого конца, который называют началом списка.
Элементы сохраняются последовательно. Но для очереди используется принцип FIFO, а не LIFO.
- Enqueue – вставка элемента в конец очереди;
- Dequeue – удаление элемента из начала очереди;
- isEmpty – будет возвращено значение True, если очередь пуста;
- Top – возвращает первый элемент из очереди.
Дек или двухсторонняя очередь
Дек (двухсторонняя очередь) – это вид списка (стека) с двумя концами. Он позволяет добавлять и извлекать элементы с двух сторон (как в начале, так и в конце).
Дек работает одновременно по FIFO и LIFO. Потому он и относится к отдельной программной единице, которая была получена в результате суммирования стека и очереди.
Графы
Графом называют набор узлов (вершин), соединенных между собой связями (называют ребра, дуги).
- ориентированными – имеют ребра с единственно возможным направлением между парой связанных вершин;
- неориентированными – для каждой дуги переход между вершинами может происходить в любом направлении, а также из каждой вершины можно перейти в другую;
- смешанные – отличаются присутствием дуг, перечисленных выше.
Графы могут иметь различную форму:
- матрицы смежности – таблицы целых чисел, в которой каждая строка либо столбец являются другим узлом на графе. В месте пересечения столбца и строки находится число, указывающее на отношение. Нули указывают, что ребер нет, а единицы – что связи есть;
- матрицы инцидентности;
- списка смежности – представлен списком, в котором левая сторона выступает вершиной, а правая – перечнем всех иных узлов, соединенных с ней;
- списка ребер.
В графах используются алгоритмы обхода:
- в глубину (depth-first search) – обход осуществляется по узлам.
- в ширину (breadth-first search) – поиск осуществляется по уровням;
Стиль дуг граф может быть не только в виде прямой линии, а вершин – выражен в цифрах. Существуют графы, именуемые взвешенными, где ребрам соответствует определенное значение (именуемое его весом). При совпадении концов ребра его называют петлей.
Графы довольно часто используются в транспортных и компьютерных сетях, веб-технологиях. По принципу граф построены социальные сети, где люди являются узлами, а дуги – их связями.
Множества
Хранение данных во множество организовано беспорядочно и без повторяющихся значений. В них можно добавлять и удалять объекты, а также есть еще ряд важнейших функций, позволяющих работать одновременно с двумя наборами функций.
Так, при двух заданных множествах функции выполнят:
- Union (объединение множеств) – объединятся все элементы, принадлежащие им обеим. Результат будет возвращен в качестве нового (не имеющего дубликатов);
- Intersection (пересечение множеств) – будет возвращено новое множество, которому будут принадлежать объекты, имевшиеся в обеих заданных множествах;
- Difference (разница множеств) – будет возвращено множество с элементами, содержавшимися в одном и не повторявшиеся в другом;
- Subset (подмножество) – возвращает булево значение, демонстрирующее содержатся ли в множестве все объекты иного.
Map также именуют ассоциативный массив или словарь. Это структура данных, которая сохраняет данные в связке уникальный ключ/ значение. Чаще всего он используется, когда необходим быстрый поиск информации
С помощью Map можно:
- добавить пару;
- удалить пару;
- изменить пару;
- найти значения, которые связаны с определенными ключами.
Хэш-таблицы
Это структуры, реализующие интерфейс Map, позволяющий сохранять пару (ключ/ значение). Хеширование применяется для нахождения в массиве значения индекса, по которому будет найдено нужное значение.
При детальном рассмотрении можно увидеть, что хэш-таблица является массивом. В нем хэш-функция является индексом.
Коллизией называют хеширование двух вводов, имеющих одинаковый цифровой выход. Цель – уменьшение числа коллизий.
Когда в хэш-таблицу вводится пара ключ/ значение, с уникальным ключом проводится хеширование, после чего он становится числом. Оно в последствии используется в качестве фактического ключа, в котором это значение хранится. При повторной попытке получить доступ к этому же ключу, хеш-функция проведет его обработку и вернет то же числовое значение, которое в дальнейшем будет использовано для нахождения связанного значения. Это способствует быстрому поиску.
Производительность хеширования зависит от:
- функций хеширования;
- параметров хэш-таблиц;
- методов устранения коллизий.
Деревья
Деревом является иерархическая структура данных. Она составлена из узлов (вершин) и дуг (ребер). При близком рассмотрении можно понять, что деревьями являются связанные графы, не имеющие цикличности.
Дереву присущи характеристики:
- Каждое имеет единственную вершину (корневой узел), расположенную сверху и не имеющую предков. Никакая вершина не ссылается на корень, а из него можно достичь любой имеющейся вершины дерева (это следствие свойства связанности древовидной структуры).
- Вершины, которые не имеют потомков (не ссылаются на иные) называются терминальными узлами (листьями).
- Объекты, которые располагаются между вершиной и листьями, называются промежуточными узлами.
- Каждая вершина древовидной структуры имеет лишь единого предка, а если он является корневым – не имеет ни одного предка.
- У корневого узла может быть от нуля или более потомков.
- У каждого дочернего узла может быть от нуля или более дочерних вершин.
Поддеревом называется часть древовидной структуры, которая имеет вершину и имеющиеся потомки.
Существует несколько типов деревьев. Чаще других встречается бинарное дерево. Оно представляет собой структуру данных с иерархией, в которой каждый узел имеет определенное значение (которое является ключом) вместе со ссылками на потомков (слева и справа).
Для деревьев используются следующие методы обхода:
- прямой – осуществляется сверху вниз (начинается с посещения предков и постепенно переходит к потомкам);
- обратный – обход осуществляется снизу вверх (прежде посещаются потомки, потом – предки);
- симметричный – обход осуществляется слева направо (по очереди осуществляется обход поддеревьев главного дерева).
Выражение информации в виде древовидных структур оправдано в том случае, если у нее есть явная иерархия. Иерархически выраженная структура потребуется при работе с данными о географических объектах, служебных должностях и т.д. В таких случаях информацию лучше представлять в виде классических математических деревьев.
Дерево двоичного (бинарного) поиска
Кроме вышеуказанных характеристик деревьев, дереву двоичного поиска характерны еще ряд характеристик:
- Узел может иметь не больше двух детей (потомков).
- Левые потомки меньше текущего узла, что меньше, чем у правых детей.
Бинарные деревья помогают существенно ускорить работу объектами (находить, удалять, добавлять их).
Префиксные деревья (Trie), боры, лучи
Префиксные деревья, именуемые иногда борами и лучами, являются разновидностью древовидных структур. Они особенно эффективны для работы со строками, т.к. обеспечивают быстрый поиск информации. По сути бор является деревом поиска.
Чаще всего боры используют для:
- поиска слов в словарях;
- автозавершений в поисковиках;
- IP-маршрутизации.
Бор хранит данные в узлах. Такие деревья часто используются для хранения слов. Они хранятся в борах сверху вниз – в каждом узле по букве.
Для записи слова необходимо проследовать по ветвям дерева, вписывая за раз по одной букве. Если порядок букв не похож на другие слова в дереве либо слово заканчивается, шаги начинают расходиться. В каждой вершине находится буква (данные) вместе с логическим значением, которое указывает на то, является ли данный узел в слове последним или нет.
Двоичная куча
Так называют полное дерево, у которого в каждом узле до двух детей. У двоичной кучи все уровни до последнего заполнены полностью. В последнем уровне заполнение ведется слева направо.
- максимальной – у родительских узлов ключи всегда больше либо равны тем ключам, которые у детей;
- минимальной – у родительских узлов ключи меньше либо равны ключам у дочерних элементов.
В двоичной куче прослеживается важность порядка между уровнями, но не между узлами одного уровня.
Это вся важная информация о структурах данных программы. Изучайте материал, находите новое и применяйте на практике. Если возникли вопросы – задавайте. Обязательно ответим на них.
Читайте также: